CONTACT-AI
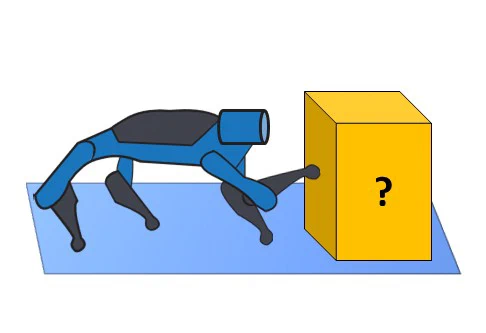
Challenge. The International Labour Organisation reports over 300 million work-related accidents and diseases per year, with nearly 3 million being fatal (ILO report). Embodied Artificially Intelligent (EAI) agents can reduce this drastically, by for example inspecting construction sites or transporting cargo through hazardous areas. However, autonomously navigating unknown environments is difficult and requires adaptive decision-making. Suppose the agent detects a visually ambiguous obstacle: is it a crate that can be pushed away? Or a fence that needs to be navigated around? Rule-based algorithms and task-priority controllers could yield unsafe situations, while reinforcement learning (RL) requires enormous amounts of trial-and-error, potentially breaking the robot during training. The challenge is to design an EAI agent that cautiously and efficiently explores using multiple sensory modalities to find the best path through unknown terrain.

Solution framework: brain-inspired multi-modal switching dynamics. We believe an agent should use touch for exploration when vision cannot resolve ambiguity in its environment (Figure 1). Mechanically, we envision an agent that transfers visual uncertainty about the external world (what is this obstacle in front of me?) to kinematic uncertainty internally (what will happen if I move my leg?), and then reacts with actions that minimize uncertainty (e.g., gently push object with leg). To create such an agent, we take inspiration from natural embodied intelligence and computational neuroscience, specifically Active Inference. An active inference agent operates on beliefs (probability distributions over unknown variables) and updates these using variational Bayesian inference when new data is observed. Using quantified uncertainty, actions are balanced between exploration (maximizing information gain during data acquisition) and exploitation (reaching a goal). It has been demonstrated to be a powerful framework for planning and navigation. Uncertainty also leads to caution: slow careful movements when uncertainty is high and rapid targeted movements when uncertainty is low.
We propose to design an active inference agent for a quadrupedal robot that incorporates visual perception, planning, decision-making and sensorimotor control (Figure 2). The active inference module learns two sets of dynamics: loco-motion and loco-manipulation. Visual perception is passed as a belief, expressed in terms of a factorized probability distribution, to the active inference module. Visual uncertainty is merged with the uncertainty in the loco-manipulation dynamics, akin to sensor fusion. When that uncertainty becomes large, the agent favours actions that minimize it in the future, such as manipulating the unknown object with its leg. Since the initial uncertainty will be high, the agent will make contact cautiously. Uncertainty shrinks with contact and a stronger action, such as pushing the object away, will be chosen, leading to a potentially improved locomotion path. In summary, the proposed active inference agent will use multiple modalities (vision, touch) to cautiously resolve ambiguity in the world and navigate the environment more robustly.
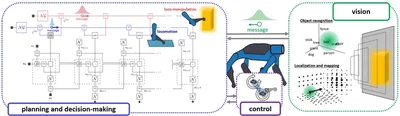
Implementation. The agent will have a vision, a control and a decision-making module (Figure 2). The vision module runs a simultaneous localization and mapping algorithm as well as rudimentary object detection. The planning and navigation module will switch between locomotion and loco-manipulation. During locomotion, it generates targets for a gait controller and guides the robot along the planned path. During loco-manipulation, it plans a series of cautious contact-rich policies that maximize information gain on the object and whether it can be pushed away. We will use switching autoregressive models, that are explainable in terms of the effect of input sources on output prediction, and for which information gain can be calculated analytically. Computations are distributed by means of reactive message passing on a Forney-style factor graph. This ensures computation cost is small enough to run in-situ (e.g., Raspberry Pi + NVIDIA Jetson) on a low-cost quadrupedal robot platform (e.g., Petoi Bittle), which we aim to demonstrate as proof-of-concept.